





GEN数据新闻奖(Data Journalism Awards, DJA)是由谷歌、骑士基金会(Knight Foundation)和全球编辑网络(Global Editors Network, GEN)共同设立的数据新闻领域最受关注大奖。今年,评委会共收到来自全球各地将近500多件参赛作品,其中78件作品入围最终各奖项角逐。评委们将从中选出10个获奖作品,并于6月18日西班牙巴塞罗那的GEN数据新闻峰会上宣布结果。
今年大会的主评委、谷歌新闻实验室的数据编辑Simon Rogers说,今年有两个亮点让他刮目相看:“不少高质量作品来自数据新闻的后起之秀;全世界正兴起一股利用开放数据结合讲故事技巧的热潮。”
“年度调查”(Investigation of the Year)是GEN数据新闻奖的十个奖项之一。今年有17个作品入围“年度调查”奖,深度君将为大家介绍几款“心头好”,跟随数据记者们一窥这些藏在数字里的秘密。
FT调查:汉能尾盘十分钟的爆发

有关中国首富李河君和他所创办的太阳能公司的报道-“汉能尾盘十分钟的爆发”,是《金融时报》目前为止所做过最有野心的数据驱动的调查,严谨的数据分析使其成为金融方面的调查报道典范。
汉能薄膜发电是汉能集团旗下的上市子公司。作为一家中国民营企业,汉能集团主要专注于薄膜太阳能技术。在不到两年时间里,汉能薄膜发电市值一路飙升,已经超过了Twitter和电动汽车制造商特斯拉(Tesla),而拥有该公司73%股份的创始人李河君成了中国最富有的亿万富翁。为了分析这只直到去年还鲜为人知的太阳能小盘股股价飙升的原因,英国《金融时报》梳理了香港最大上市公司的1.4亿次单笔交易。
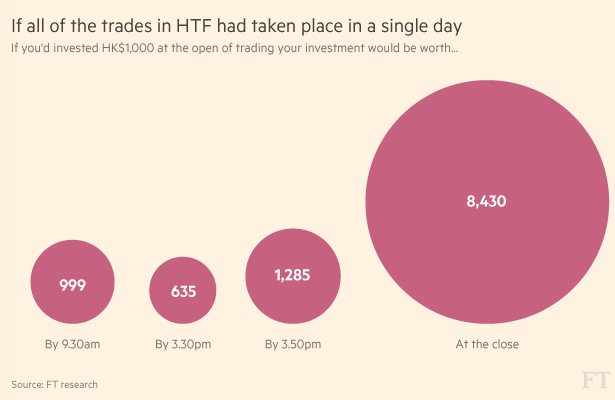
自今年一月,《金融时报》就开始关注汉能集团,他们想搞清楚这个太阳能公司如何在两年内达到了355亿美元市值。今年二月份,金融时报不同团队的记者们(从数据、交互,到金融、绘图)跨部门通力合作,用数周时间分析了该上市公司以分钟计的交易数据,最终发现一个非同寻常的交易模式:从2013年初到今年2月份,这间太阳能公司的股票总在尾盘时分出现飙升,时间大约在收盘前10分钟。这种暴涨极有可能是这只股票过去两年惊人的股票增长背后的动力,并且,《金融时报》的分析也表明,几乎没有其它股票在尾盘有如此活跃的表现。

这篇调查报道于2015年3月24日发表后在中英文媒体间引发极大关注和诸多跟进报道,FT的网页流量也呈螺旋式上升,为报道所制作的音频节目有至少十万人收听,不少读者留言肯定该报道的严谨程度。这个调查让人们质问谁在操纵股市,以及随着中国市场扩张、大陆投资者在境外寻求更多机会,香港股市是否得到足够监控。《金融时报》这次调查精确、公允,并且大量使用图表推进调查结果,堪称他们最成功的公共利益报道之一。
英国《金融时报》的分析方法
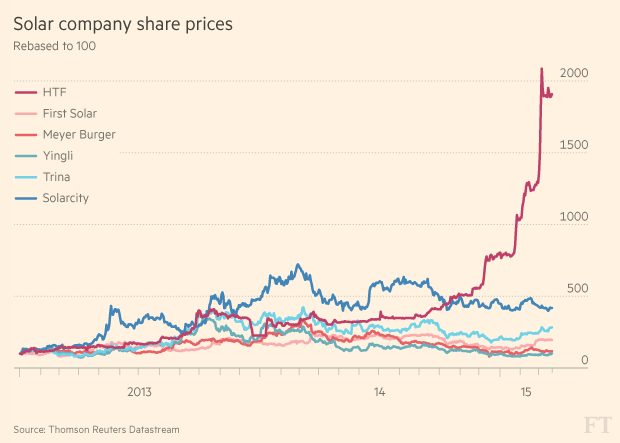
英国《金融时报》分析了汉能薄膜发电从2013年1月2日到2015年2月9日期间在香港股市的每笔交易数据。
英国《金融时报》以10分钟为单位划分了这些数据,并跟踪了每个10分钟开头和结尾的交易价格。整套数据共有1.4亿个数据节点。汉能薄膜发电的数据是根据每日交易情况编制的,占了其中逾80万个数据节点。
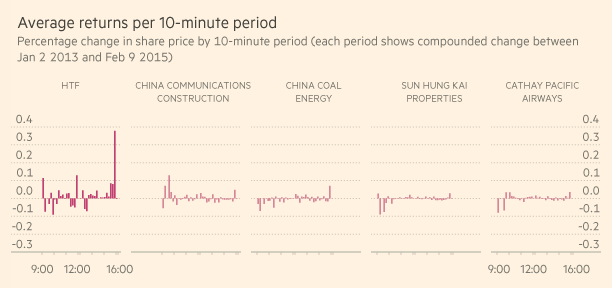
回报则是用两种不同方法计算的。在第一种方法中,英国《金融时报》计算了交易日中每个10分钟片段中第一笔交易和最后一笔交易的价格差异。在第二种方法中,英国《金融时报》比较了一个10分钟片段中的第一笔交易与后一个片段中第一笔交易的价格差异,还比较了一天的开盘价与此前一天的收市价。
基于这些数据,英国《金融时报》计算了这只股票在上述期间每10分钟的平均回报和复合回报,也用同样的方法计算了每月和每日的回报,并与随机选取的其它几支香港上市的股票做了比较。在分析过程中,英国《金融时报》使用了SQL数据库查询语言及统计编程语言R语言。
WSJ调查:医保解密
“医保解密”是美国《华尔街日报》所做的一系列数据驱动的调查报道,内容有关美国信息透明度极低的医保系统:6000亿美金的医保账单是如何被花出去的?
这一系列报道最终使得美国政府被迫于2014年4月首次公开了自1979年以来一直保密的重要医保数据,《华尔街日报》也在数据公开后继续跟进一系列全面调查,分析和披露医保体系如何滥用纳税人的钱。
政府得以公开这些信息,主要归功于《华尔街日报》母公司道琼斯的胜诉,以及《华尔街日报》记者团队锲而不舍的报道和跟进。《华尔街日报》利用这些新公布的数据,勾勒出医疗与贪婪在美国医保体系中的勾结,美国纳税人每年至少掏出600亿美金为伪造的医保款项买单。
这一系列的报道被称为“医疗解密”,并产生行业震荡。比如,其中一篇文章检视了类似卡氏肺囊虫肺炎(PCP)等非常见疾病的体检项目和药物的昂贵费用,随后,医保管理机构-美国医疗保险和医疗补助服务中心(CMS)正式否决了覆盖更多体检项目的提案,并考虑下一年中实施改革措施,以控制超额的开销。另一个重磅调查则找出一些手术收费和利润明显比其他人高的医疗供应商,没过多久,美国联邦调查局(FBI)便开始立案调查其中一个供应商。
“医疗解密”系列并非简单呈现所获得的数据,而是由一个调查记者和数据专家所组成的团队分析和搞懂这些数字背后的联系,并制作了一系列互动图和表格,条理清晰,有大量细节呈现。
《华尔街日报》花费了大量时间、金钱和记者资源使这一系列调查得以诞生。多年来,美国政府一直拒绝提供医保账单的信息。而当美国医疗保险和医疗补助服务中心(CMS)终于在2010年4月公开相关信息时,他们也没有提供任何针对这些数字的分析。这对华尔街日报的团队是极大挑战,他们必须确保调查结果的公平合理和数据分析的准确,避免针对任何具体医护人员。他们分析了这个数据组中的920万条记录,从而在2014年发表这一系列名为“医疗解密”的报道,这组文章向人们揭示了这个原本为老年人和残障人士所设置的,涉及6000亿美元的庞大工程之运作内幕。
《华尔街日报》的分析方法
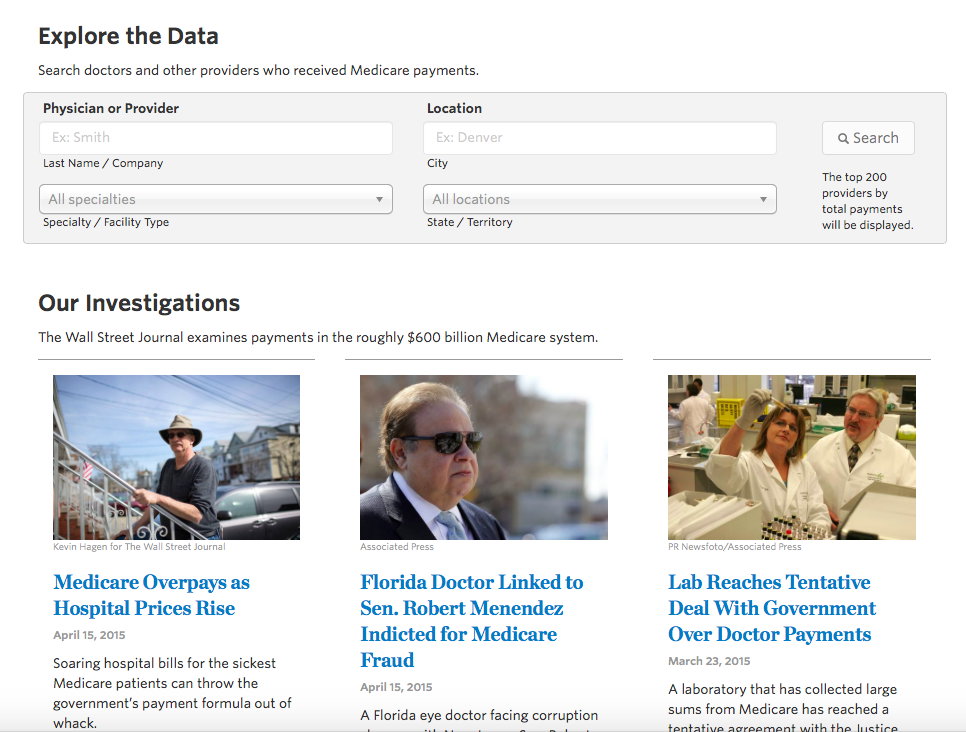
储存和分析整套医保系统数据是个相当复杂的工程,但它却是这一数据调查运作的基石。
整套数据由两部分组成:一部分是政府公开的数据表格,总共包含大概1000万条记录;另一部分则是政府公开信息前,由《华尔街日报》向CMS花钱申请的数据,多达几十亿条记录,其中有过去六年多里大量记账人每一条账目的细节。
光是查询后一数据集就要花上几天时间,写代码分析则更是艰巨任务。为了能将数据导入Microsoft SQL数据库,记者们用C#语言写程序,把几百行的表格记录处理成可以用来返回有意义结果的关系表格。
为了确保工作内容的可重复性,数据记者们通常用R写代码来进行分析。他们利用了大量分析工具研究这些数据,包括线性回归、逻辑回归、主成分分析、K均值算法和多种期望最大化算法。尽管这些工作并不都能在最终成果中得以呈现,但这一步骤对于记者了解具体调查线索和数据中整体模式之间的相关性是至关重要的。
《华尔街日报》的交互图表团队在数据被公开当天也同时发布了一个可供搜索的医保供应商数据库。随后的几周乃至几个月时间里,团队不断在该数据库上添加新的功能和深度,并最终将这个项目叫做“医保解密:数字背后”。这个交互现在是“医保解密”系列报道的封面,它呈现了88万医保系统中的医生和供应商的信息,让任何人都能很容易查到每一地理位置和专业科室中的最大受益人。
该数据库也添加了每一供应商账单数据的背景信息,帮助人们理解这900多万个数据节点中存在的联系。这个可做搜索的数据库是用REST API制作的。查询请求会通过PHP发送到一个MySQL服务器上,再向浏览器返回JSON格式的数据。他们使用了PHP中一个简单的缓存,避免重复查询数据库中的一般查询指令。浏览器的展示使用了HTML,Javascript和PHP。

本作品采用 知识共享许可协议 署名-禁止演绎 4.0 国际 进行许可
您可以根据知识共享协议条款免费转载这篇文章
转载
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
阅读更多

数据新闻
数据新闻中最常见的10个错误
在今年的 NICAR 会议上,GIJN 与几位数据新闻专家交谈,询问他们在数据新闻中最常见的10个错误,包括忽视空白行、混淆百分比和百分点、在图表中使用错误的刻度尺等等。

数据新闻
新冠三年,记者们围绕它展开了哪些调查?
自第一例已知的新冠病例被发现的三年时间里,世界各地的调查记者已经对这个现代史上最困难的公共卫生选题进行了诸多调查。在这篇文章中,我们回顾了其中最具创新性和影响力的调查报道。

深度报道技巧
跨境调查远洋渔业,《Ocean Inc.》是如何做到的?
“环境报道联盟”的跨境调查《海洋有限公司》获得了2022年SOPA卓越环境报道奖,这组报道由14间新闻机构和来自13个国家的记者合作进行。他们是如何协调来自不同文化和背景的记者?又有什么调查经验值得借鉴?全球深度报道网采访了参与项目的记者和编辑。

深度报道技巧
《纽约时报》团队如何调查战争中的平民伤亡?
今年普利策奖国际报道奖得主是《纽约时报》关于美军空袭造成叙利亚平民伤亡的报道,在这篇文章中,这组报道的参与者分享了他们是如何想到这个选题,以及如何利用开源工具、数据库和公开信息申索而最终完成了这篇重磅调查的。