
年度数据调查故事 (二):半岛电视台特辑




GEN数据新闻奖(Data Journalism Awards, DJA)是由谷歌、骑士基金会(Knight Foundation)和全球编辑网络(Global Editors Network, GEN)共同设立的数据新闻领域最受关注大奖。今年,评委会共收到来自全球各地将近500多件参赛作品,其中78件作品入围最终各奖项角逐。评委们将从中选出10个获奖作品,并于6月18日西班牙巴塞罗那的GEN数据新闻峰会上宣布结果。
今年大会的主评委、谷歌新闻实验室的数据编辑Simon Rogers说,今年有两个亮点让他刮目相看:“不少高质量作品来自数据新闻的后起之秀;全世界正兴起一股利用开放数据结合讲故事技巧的热潮。”
“年度调查”(Investigation of the Year)是GEN数据新闻奖的十个奖项之一,今天深度君跟大家继续分享“年度调查”入围作品中来自半岛电视台美国频道(Al Jazeera America)两个充分结合数据与多媒体的故事。
作品一:夹缝生存-贫困线以上,中产以下
In Between in California

故事背景:
半岛电视台的In Between California把报道中心锁定于那些在贫困线以上,却远没有资格迈入中产行列的“贫困人群”。今年恰逢美国前总统林登·约翰逊“向贫困宣战”系列政策颁布的五十周年。在此政策影响下,美国曾出台众多如“食品券”“医疗保险”等保障措施,但新闻媒体对于贫困的报道则相对单一,通常从政策的角度切入,重点关注扶贫的政府项目和机构。问题在于报道经常将穷人作为“他者”——设定成“不公平制度的受害者”,或者是经常吃救济饭的“救济大王”,不值得富裕人群出手相助。半岛电视台此次将“人性”重新带到报道当中,只将重点放在那些和贫困缠斗的人们身上。
分析方法:
报道选取了5个加州家庭作为报道对象。为了解释清楚他们的困境,团队专门收集了有关家庭开销、收入金额和开支规划的信息,并把不同家庭的数据拼贴起来展示给读者。
报道以对话开始,半岛电视台希望把和读者的对话作为采访报道的一部分,深入探讨贫困的定义以及他们自己的贫困经历。
鼓励读者参与活动的网站内容截图
多媒体技术:
半岛电视台的网络报道图文并茂,使用了HTML, CSS, JavaScript完善网页图片效果,将权威机构的数据做成直观的图表,让读者清晰了解加州贫困人群的工资水平和生活质量。也使用了谷歌地图显示贫困家庭的分布,并且结合Illustrator、Photoshop等处理软件将网页设计的动态图画制作出来,形成互动、多维的网络展示模式。
作品2:“吉姆·克劳”法的卷土重来
Jim Crow returns

故事背景:
半岛电视台历时6个月、分两部分调查了美国地方选举情况,从中发现27个州的选举官员(大部分是民主党人)为了清除同一场选举中从不同州非法重复投票的投票者名单,设计了名为“州际核查”(Interstate Crosscheck)的电脑程序,将成千上万来自关键选区的非洲裔、拉美裔和亚裔的选民排除在有效投票名单之外。在半岛电视台从佐治亚州、维吉尼亚州和华盛顿州获取的名单中,大部分选民的名字都是少数族裔的名字,而且大都是共和党人的拥护者。最终他们发现有七分之一的非洲裔选民、八分之一的亚裔选民和八分之一的拉美裔选民名列其中,甚至有十一分之一的白人选民也会面临被选举名单清除的风险,但是少数族裔仍然是首当其冲的受害者。
分析方法:
半岛电视台先以《信息自由法》为依据向24个州提出了获取投票名单的申请,最终获得了来自佐治亚州、维吉尼亚州和华盛顿州三个周的州际核查名单,共包含两百万个名字。经排查,每一个名单上的选民都称自己只在一个州投过一次票。整个团队使用美国人口调查局的公开文件(其中包含2010年普查得出的最常用姓氏的名单和所属的种族背景),结合来自皮尤研究中心(Pew Research Center)的各个州选民数据,整合成一个数据库,可供分析、排序、量化。同时,将州际核查名单上的名字分成白人、黑人、拉美裔、亚裔/太平洋区人或者印第安人/阿留申人组别,以判断在此名单中少数族裔被忽视的程度,再将分析结果推演到其他的州。
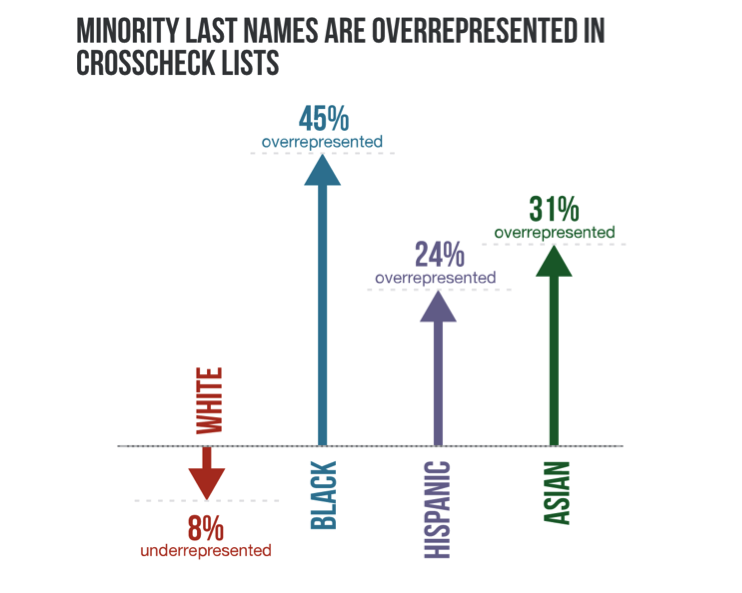
洲际核查名单中的组别分布截图
多媒体技术:
分析师所组成构建的数据库共收纳了一百二十万个名字,整个团队将结果的数量和每一个搜索结果的字母一一比对,总结出了美国最常见的25个姓氏的名单。为了能更快地呈现结果,多媒体团队将所有名字分为三组:维吉尼亚州的名字、佐治亚州的名字、以及来同时来自这两个州或来自两个州中任一个州的名字。每个组都包含JSON格式的文件,也都有例如AAB,AAD,AAG这样的字母组合——这样用户一键入字母“A”,就能马上搜索到只包含A的文件,在键入第二个第三个字母时能进一步缩小搜索范围。
半岛电视台使用了Python的电子数据表格和JSON处理数据库,整合了不同州、不同的格式的数据表(其中包括例如jQuery、Underscore和Handlebars这样的Javascript数据库),迅速制作出兼容不同浏览器的界面,保证持续、清晰地呈现数据。同时团队还采用了一系列专为Tarbell(一个由《芝加哥论坛报》员工开发的应用程序)设计的页面模板,该应用还能连接谷歌云盘,编辑可修改文本,研发者也能将可供搜索的数据库和最终的报道页面相结合,使之相辅相成。
编译:周炜乐

本作品采用 知识共享许可协议 署名-禁止演绎 4.0 国际 进行许可
您可以根据知识共享协议条款免费转载这篇文章
转载
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
阅读更多

GIJC 侧记 GIJC23
#GIJC23 侧记:危险者的聚会
“如果把这两千多个人都消灭了,全世界的独裁者应该会睡个好觉。”在 GIJC23 现场,我们一直开这样的“地狱玩笑”,却又如同另类的集体心理诊疗。自由作者邹思聪在这篇侧记中讲述了三位俄罗斯流亡记者的故事——他们虽然再也无法回国,却在异乡坚持报道、建立生活。

GIJC 侧记 GIJC23
#GIJC23 侧记:哪怕空间再小,也不要停止做事
在参会之前,于月想知道这个世界上有没有哪些同行和我们一样处境艰难,又是怎样克服?在听到来自世界各地的同行分享后,她觉得哪怕空间再小,也不要停止做事。


GIJC 侧记 GIJC23 全球深度报道大会
GIJC 侧记:残缺的数据,模糊的面孔,天秤倾斜的判决——从女性杀戮报道说起
如今我们究竟需要怎样的报道?在影响力如此受限的当下,我们究竟如何定义和看待“impact”?在报道杀戮女性的分享中,独立记者易小艾找到了部分答案:有些记录,若没有留下,真的会丢,若还有一些力气,就一起守住每一个留下记录的可能吧。